Best Practices
Constructing easy to follow Mambu Process Orchestrator (MPO) processes is a key part of keeping your flows maintainable, readable, and debuggable. For most processes we suggest the following general principles:
- We recommend splitting your work into two parts:
- A static part where your state diagrams store the URLs, credentials, and configurations for accessing APIs or sandbox and production Mambu tenants.
- A dynamic part where you have the processes that run the business logic of your application. In this way you can easily deploy stages of your processes without having to re-populate your state diagrams.
- Extract separate business flows into subprocesses that are called by the main process. In the same way one could use functions in certain programming languages.
- Adopt a numbering system to keep track of subprocesses. For example:
- Main process (which calls the subprocesses when needed)
- Subprocesses:
- 1.1. Client creation
- 1.2. Order placement
- 1.3. Order confirmation
- Subprocesses:
- Main process (which calls the subprocesses when needed)
- Avoid passing the configuration object from the main process to subprocesses. Each subprocess should only read the configuration data it uses directly.
- Visually design your processes in a way that follows the logic. A top-to-bottom, left-to-right, or right-to-left layout that tracks the progression of the process is easier to follow than one with nodes in random locations.
- Any additional logic, such as constructing the payload for an API call, should be done outside the method. The API methods should be clean and easy to call from different flows of the connector.
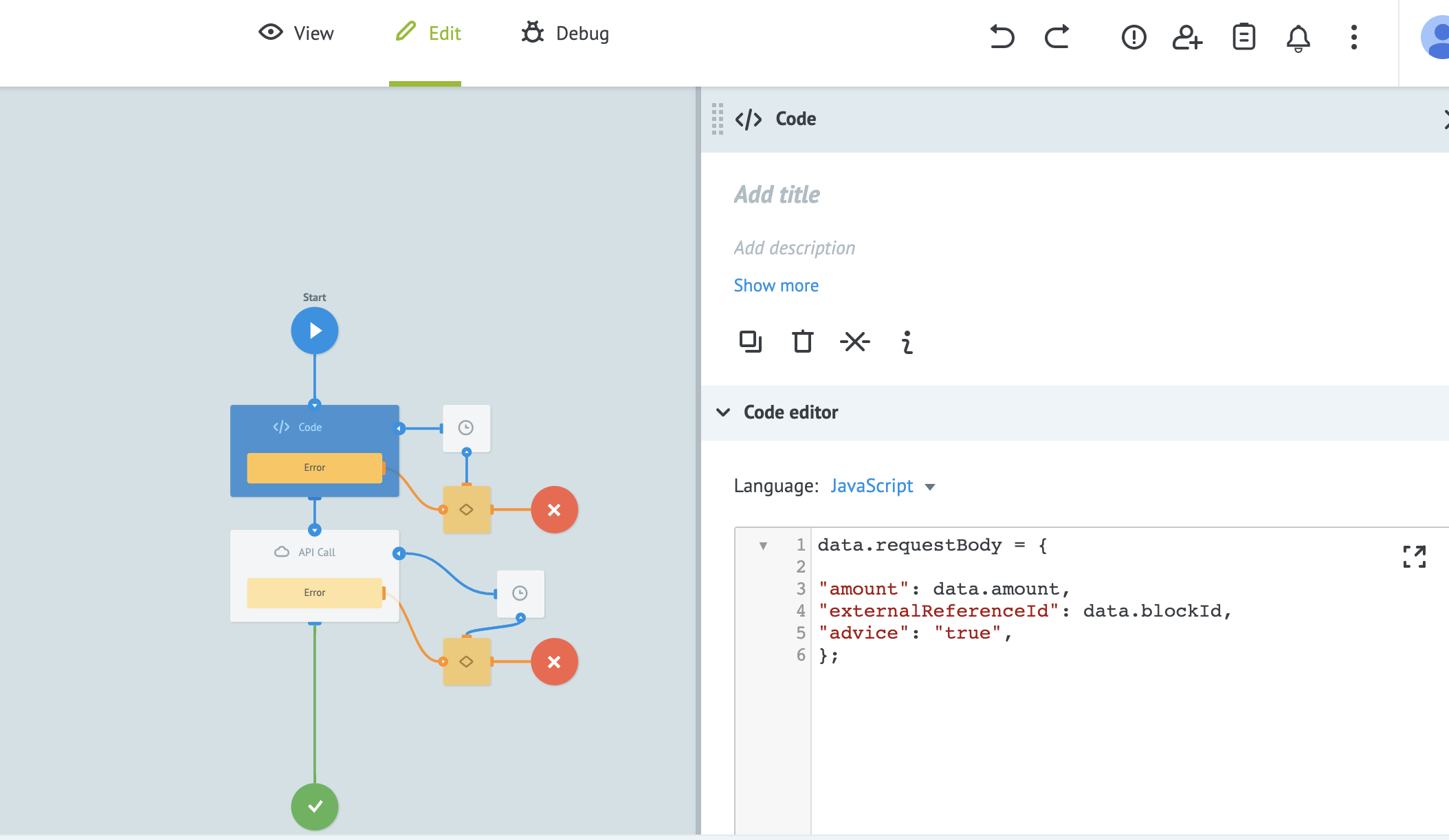
- For usability purposes, we recommend that API calls are built with
Request format = Raw. This allows you to send payloads from multiple flows of the process without modifying the API call.
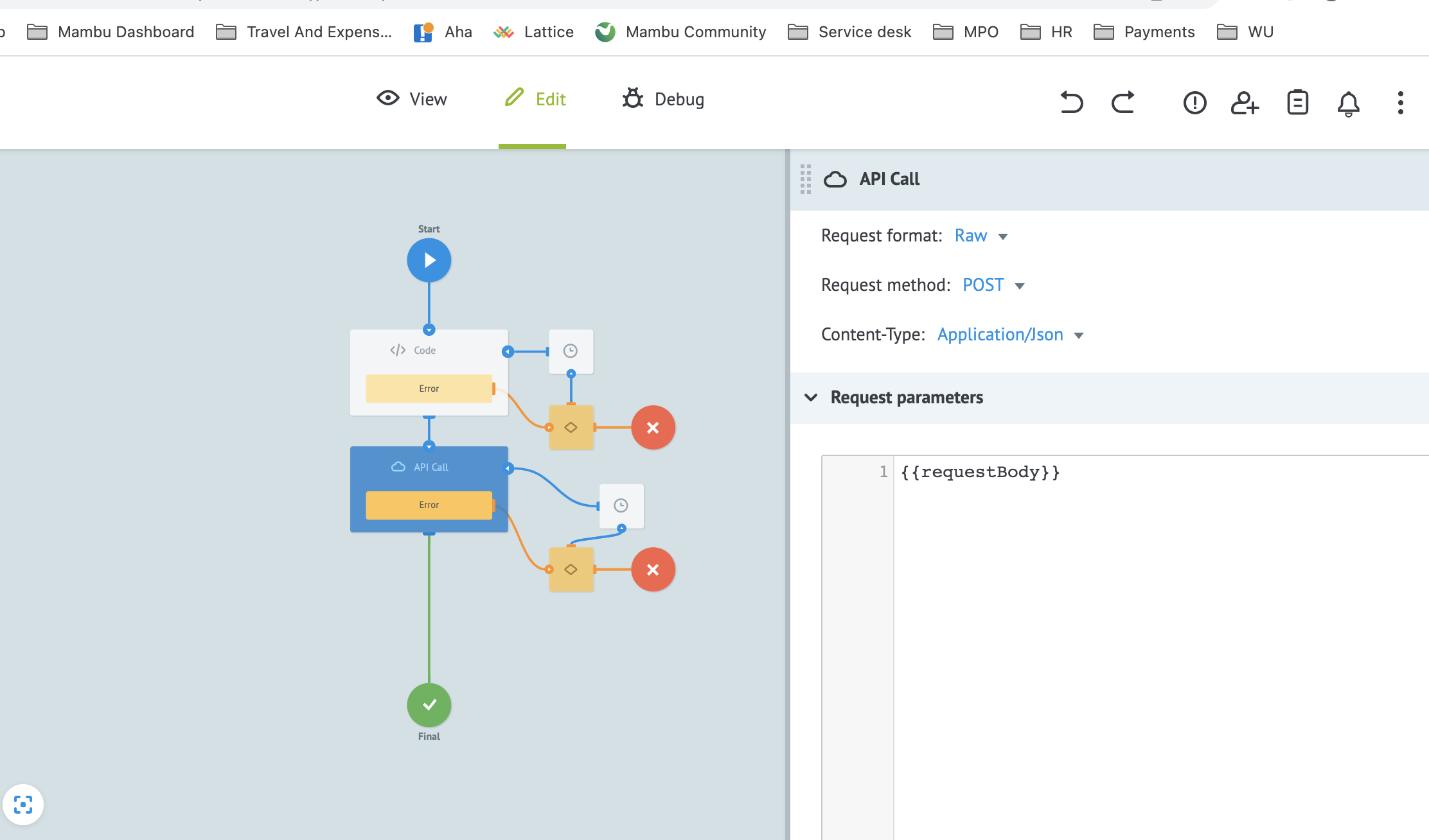
- Use descriptive names for your variables and be careful where you have similar names. For example, the variable
accountIdmay mean different things and it would be preferable to name a variableloanAccountIdordepositAccountIdto avoid confusion. - As connectors work with multiple systems, when you have similar variable names make sure you name your variables according to the system that uses it. For example, instead of using
clientas a variable name, usemambuClientIdorncinoClientIdto better differentiate variables. - Avoid overwriting and renaming variables within a process.
- All nodes should have a short descriptions, especially End:Success and End:Error final nodes, to help you debug processes when they fail.
Beyond these principles there are development areas that require special attention when building flows.
Data security
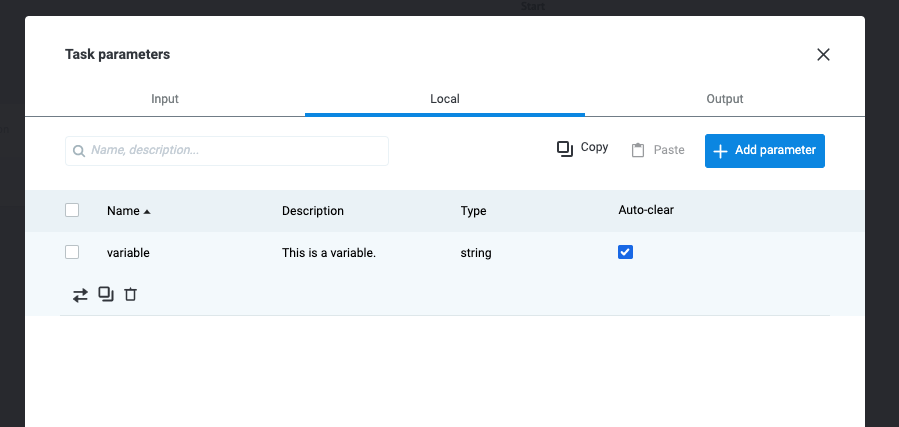
Sensitive data - such as passwords, authentication keys, secret keys, and IBANs - should always be hidden within MPO processes and configuration state diagrams. Add sensitive data as Task Parameters > Local parameters and enable Auto-clear. This hides the values in the process.
Performance improvements
In some areas you may get small performance improvements from these tips and tricks. In most cases, the MPO platform is designed for best performance - but there are ways to squeeze out more.
Reading configuration data from state diagrams
Although it is possible to read configuration data from a state diagram by using a Call Process node, it is quicker and less error-prone to read configuration data from a state diagram using the following snippet:
{{conv[STATE_DIAGRAM_ID_OR_ALIAS].ref[TASK_REFERENCE].PARAMETER}}
The STATE_DIAGRAM_ID_OR_ALIAS is the process ID of the state diagram that you want to retrieve configuration data from. Note that this is the process ID and not the task ID. The TASK_REFERENCE is the reference you used or the one that was created to initiate a new task in the state diagram.

The PARAMETER is the individual parameter you want to retrieve from the state diagram. Without this value the entire task JSON will be returned.
Limiting task payload size
The payload of a task is the JSON object that travels through nodes inside an MPO process. Larger payloads can cause performance issues for the process as a whole. There is a size limit in place for posting data to MPO, but the task payload can be modified and increased once it has entered a process and this can cause performance and stability issues. We recommend keeping task payload sizes lower than 128KB, where possible.
You can do following to keep your payloads small:
- Use shorter field names.
- Split JSONs into smaller chunks by using pagination.
- Avoid using big data structures - such as big arrays and lists - in the Code node.
- Minimise the use of temporary variables that store duplicated data in the task.
- Explicitly define the data fields to be added to the task body from responses in API Call nodes.
Please Note:
To mitigate issues caused by oversized payloads, MPO has a maximum task size limit of 512KB. Payloads larger than this will return an error informing you that the task size is over the limit:
{
"__conveyor_code_return_description__": "Your task size: ***** bytes, Max available task size: 524288 bytes, Try to change your data or try to split your task: { ... ",
"__conveyor_code_return_type_error__": "software",
"__conveyor_code_return_type_tag__": "code_return_size_overflow"
}
Error handling
You can handle errors in the following ways:
- You can choose to handle errors in a different subprocess.
- You can handle errors in the same process.
- You can copy the errors to an errors state diagram for future reference.
- You can send notifications through your preferred channels when errors occur.
Handling errors in subprocesses
Use the Reply to Process node to pass on errors in subprocesses to the main process, where you can define conditions to take actions depending on the error received. When an error is returned to the main process, the error parameters can be directly stored in the errors state diagram without any further manipulation.
Handling errors that occur in calling a subprocess
Additional actions are needed when an error occurs in the Call Process node and the task does not even hit the subprocess. The conveyor parameter __conveyor_rpc_return_description__ is returned by MPO and contains the error caused by the task not having the necessary data to enter the called subprocess. Adding this parameter to the error condition node allows you to exit the Call Process node through a specific path and handle this type of error separately.
For example, a Set Parameter node can be used to capture error messages that are specific to this type of failure. The condition to use is: __conveyor_rpc_return_description__ != null and it should be the last condition in the block of conditions (using the OR operator).
Handling errors from race conditions when calling subprocesses
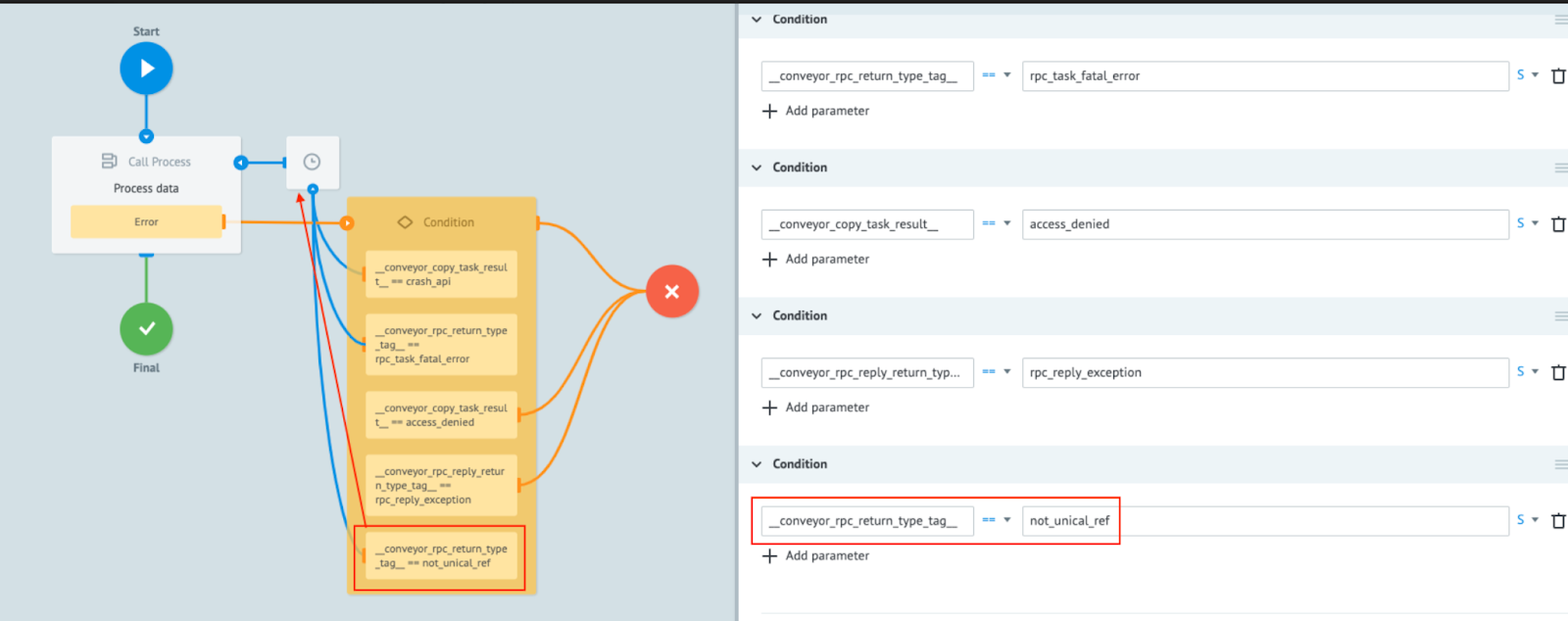
When two or more tasks enter a subprocess at the same time and MPO cannot handle the creation of two unique IDs at the same time for the tasks in the subprocess, a unique error is thrown. To handle this situation do the following:
- Extend the Condition node attached to the Call Process node.
- Add the
__conveyor_rpc_return_type_tag__ == not_unical_refcondition at the end. - Link the Condition node to the Delay node attached to the Call Process node.
Special use cases
Handling cryptocurrencies
You may set up cryptocurrencies in Mambu that go up to 18 decimal places. For more information, see Currencies in our User Guide.
However, MPO natively manages calculations on numbers with up to 6 decimal places. To perform calculations in MPO on cryptocurrencies with more than 6 decimal places, you may use a Code node with custom JavaScript that can extract full precision values from a Mambu API payload. If you require further assistance, please reach out to your Customer Success Manager.